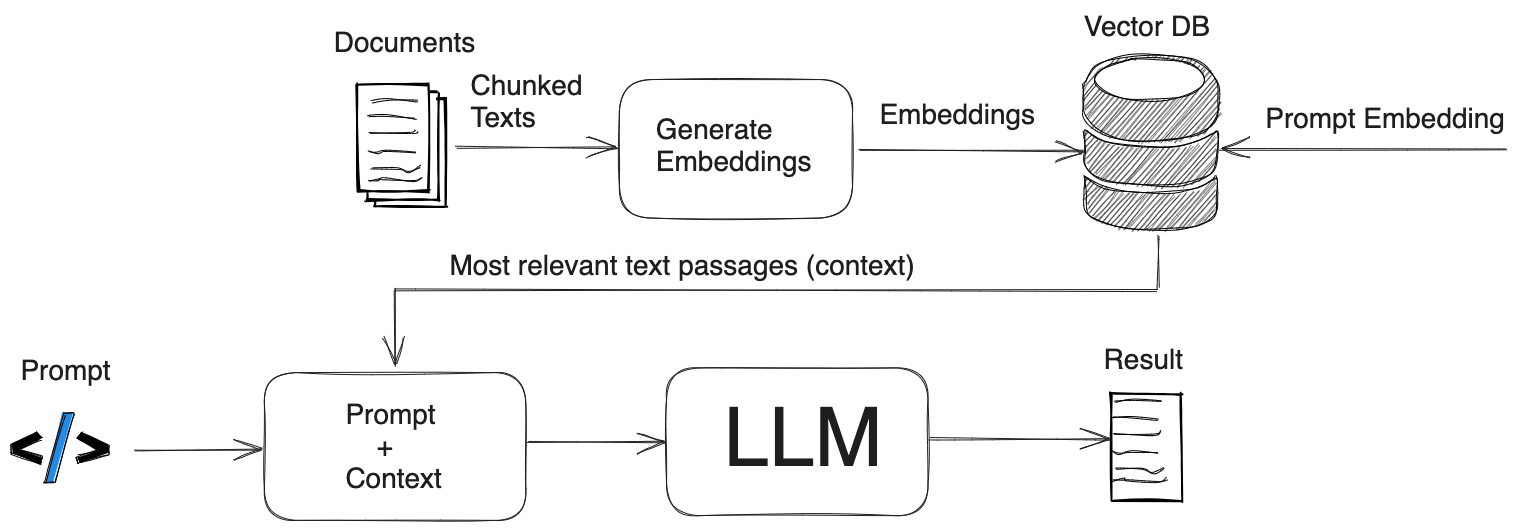
Introduction
Vector databases are a relatively new way for interacting with abstract data representations derived from opaque machine learning models such as deep learning architectures. These representations are often called vectors or embeddings, and they are a compressed version of the data used to train a machine learning model to accomplish a task like sentiment analysis, speech recognition, object detection, and many others.
These new databases shine in many applications like semantic search and recommendation systems, and here, we’ll learn about one of the most popular and fastest growing vector databases in the market, Qdrant.
What Are Vector Databases?
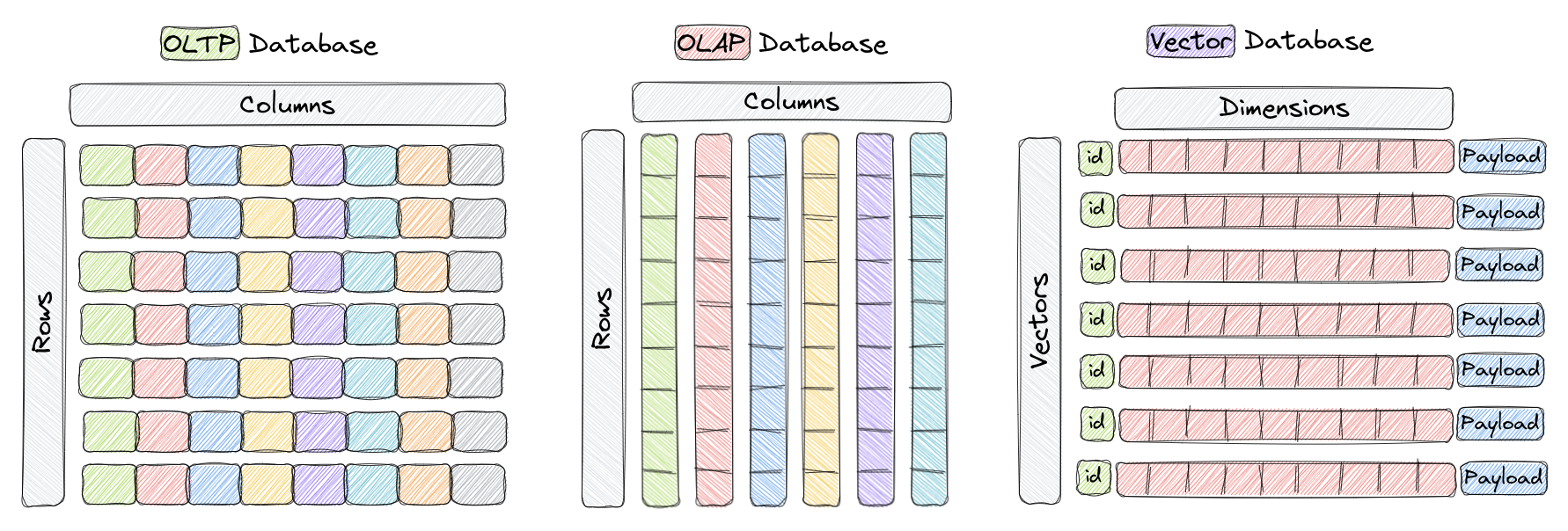
Vector databases are a type of database designed to store and query high-dimensional vectors efficiently. In traditional OLTP and OLAP databases (as seen in the image above), data is organized in rows and columns (and these are called Tables), and queries are performed based on the values in those columns. However, in certain applications including image recognition, natural language processing, and recommendation systems, data is often represented as vectors in a high-dimensional space, and these vectors, plus an ID and a payload, are the elements we store in something called a Collection within a vector database like Qdrant.
Info
A vector in this context is a mathematical representation of an object or data point, where elements of the vector implicitly or explicitly correspond to specific features or attributes of the object.
For example, in an image recognition system, a vector could represent an image, with each element of the vector representing a pixel value or a descriptor/characteristic of that pixel. In a music recommendation system, each vector could represent a song, and elements of the vector would capture song characteristics such as tempo, genre, lyrics, and so on.
Vector databases are optimized for storing and querying these high-dimensional vectors efficiently, and they’re often using specialized data structures and indexing techniques such as Hierarchical Navigable Small World (HNSW) – which is used to implement Approximate Nearest Neighbors – and Product Quantization, among others. These databases enable fast similarity and semantic search while allowing users to find vectors that are the closest to a given query vector based on some distance metric. The most commonly used distance metrics are Euclidean Distance, Cosine Similarity, and Dot Product, and these three are fully supported Qdrant.
Here’s a quick overview of the three:
- Cosine Similarity - Cosine similarity is a way to measure how similar two vectors are. To simplify, it reflects whether the vectors have the same direction (similar) or are poles apart. Cosine similarity is often used with text representations to compare how similar two documents or sentences are to each other. The output of cosine similarity ranges from -1 to 1, where -1 means the two vectors are completely dissimilar, and 1 indicates maximum similarity.
- Dot Product - The dot product similarity metric is another way of measuring how similar two vectors are. Unlike cosine similarity, it also considers the length of the vectors. This might be important when, for example, vector representations of your documents are built based on the term (word) frequencies. The dot product similarity is calculated by multiplying the respective values in the two vectors and then summing those products. The higher the sum, the more similar the two vectors are. If you normalize the vectors (so the numbers in them sum up to 1), the dot product similarity will become the cosine similarity.
- Euclidean Distance - Euclidean distance is a way to measure the distance between two points in space, similar to how we measure the distance between two places on a map. It’s calculated by finding the square root of the sum of the squared differences between the two points’ coordinates. This distance metric is also commonly used in machine learning to measure how similar or dissimilar two vectors are.
Now that we know what vector databases are and how they are structurally different than other databases, let’s go over why they are important.
Payload
One of the significant features of Qdrant is the ability to store additional information along with vectors. This information is called payload in Qdrant terminology.
Qdrant allows you to store any information that can be represented using JSON.
Installation requirements
CPU and memory
The preferred size of your CPU and RAM depends on:
- Number of vectors
- Vector dimensions
- Payload and their indexes
- Storage
- Replication
- How you configure quantization
Our Cloud Pricing Calculator can help you estimate required resources without payload or index data.
Storage
For persistent storage, Qdrant requires block-level access to storage devices with a POSIX-compatible file system.
Distributed deployment
Since version v0.8.0 Qdrant supports a distributed deployment mode. In this mode, multiple Qdrant services communicate with each other to distribute the data across the peers to extend the storage capabilities and increase stability.
How many Qdrant nodes should I run?
The ideal number of Qdrant nodes depends on how much you value cost-saving, resilience, and performance/scalability in relation to each other.
- Prioritizing cost-saving: If cost is most important to you, run a single Qdrant node. This is not recommended for production environments. Drawbacks:
- Resilience: Users will experience downtime during node restarts, and recovery is not possible unless you have backups or snapshots.
- Performance: Limited to the resources of a single server.
- Prioritizing resilience: If resilience is most important to you, run a Qdrant cluster with three or more nodes and two or more shard replicas. Clusters with three or more nodes and replication can perform all operations even while one node is down. Additionally, they gain performance benefits from load-balancing, and they can recover from the permanent loss of one node without the need for backups or snapshots (but backups are still strongly recommended). This is most recommended for production environments. Drawbacks:
- Cost: Larger clusters are more costly than smaller clusters, which is the only drawback of this configuration.
- Balancing cost, resilience, and performance: Running a two-node Qdrant cluster with replicated shards allows the cluster to respond to most read/write requests even when one node is down, such as during maintenance events. Having two nodes also means greater performance than a single-node cluster, while still being cheaper than a three-node cluster. Drawbacks:
- Resilience (uptime): The cluster cannot perform operations on collections when one node is down. Those operations require >50% of nodes to be running, so this is only possible in a 3+ node cluster. Since creating, editing, and deleting collections are usually rare operations, many users find this drawback to be negligible.
- Resilience (data integrity): If the data on one of the two nodes is permanently lost or corrupted, it cannot be recovered aside from snapshots or backups. Only 3+ node clusters can recover from the permanent loss of a single node since recovery operations require >50% of the cluster to be healthy.
- Cost: Replicating your shards requires storing two copies of your data.
- Performance: The maximum performance of a Qdrant cluster increases as you add more nodes.
In summary, single-node clusters are best for non-production workloads, replicated 3+ node clusters are the gold standard, and replicated 2-node clusters strike a good balance.
Enabling distributed mode in self-hosted Qdrant
To enable distributed deployment - enable the cluster mode in the configuration or using the ENV variable: QDRANT__CLUSTER__ENABLED=true.
cluster:
# Use `enabled: true` to run Qdrant in distributed deployment mode
enabled: true
# Configuration of the inter-cluster communication
p2p:
# Port for internal communication between peers
port: 6335
# Configuration related to distributed consensus algorithm
consensus:
# How frequently peers should ping each other.
# Setting this parameter to lower value will allow consensus
# to detect disconnected node earlier, but too frequent
# tick period may create significant network and CPU overhead.
# We encourage you NOT to change this parameter unless you know what you are doing.
tick_period_ms: 100By default, Qdrant will use port 6335 for its internal communication. All peers should be accessible on this port from within the cluster, but make sure to isolate this port from outside access, as it might be used to perform write operations.
Additionally, you must provide the --uri flag to the first peer so it can tell other nodes how it should be reached:
./qdrant --uri 'http://qdrant_node_1:6335'Subsequent peers in a cluster must know at least one node of the existing cluster to synchronize through it with the rest of the cluster.
To do this, they need to be provided with a bootstrap URL:
./qdrant --bootstrap 'http://qdrant_node_1:6335'The URL of the new peers themselves will be calculated automatically from the IP address of their request. But it is also possible to provide them individually using the --uri argument.
USAGE:
qdrant [OPTIONS]
OPTIONS:
--bootstrap <URI>
Uri of the peer to bootstrap from in case of multi-peer deployment. If not specified -
this peer will be considered as a first in a new deployment
--uri <URI>
Uri of this peer. Other peers should be able to reach it by this uri.
This value has to be supplied if this is the first peer in a new deployment.
In case this is not the first peer and it bootstraps the value is optional. If not
supplied then qdrant will take internal grpc port from config and derive the IP address
of this peer on bootstrap peer (receiving side)After a successful synchronization you can observe the state of the cluster through the REST API:
GET /clusterExample result:
{
"result": {
"status": "enabled",
"peer_id": 11532566549086892000,
"peers": {
"9834046559507417430": {
"uri": "http://172.18.0.3:6335/"
},
"11532566549086892528": {
"uri": "http://qdrant_node_1:6335/"
}
},
"raft_info": {
"term": 1,
"commit": 4,
"pending_operations": 1,
"leader": 11532566549086892000,
"role": "Leader"
}
},
"status": "ok",
"time": 5.731e-6
}Note that enabling distributed mode does not automatically replicate your data.
Making use of a new distributed Qdrant cluster
When you enable distributed mode and scale up to two or more nodes, your data does not move to the new node automatically; it starts out empty. To make use of your new empty node, do one of the following:
- Create a new replicated collection by setting the replication_factor to 2 or more and setting the number of shards to a multiple of your number of nodes.
- If you have an existing collection which does not contain enough shards for each node, you must create a new collection as described in the previous bullet point.
- If you already have enough shards for each node and you merely need to replicate your data, follow the directions for creating new shard replicas.
- If you already have enough shards for each node and your data is already replicated, you can move data (without replicating it) onto the new node(s) by moving shards.
Raft
Qdrant uses the Raft consensus protocol to maintain consistency regarding the cluster topology and the collections structure.
Operations on points, on the other hand, do not go through the consensus infrastructure. Qdrant is not intended to have strong transaction guarantees, which allows it to perform point operations with low overhead. In practice, it means that Qdrant does not guarantee atomic distributed updates but allows you to wait until the operation is complete to see the results of your writes.
Operations on collections, on the contrary, are part of the consensus which guarantees that all operations are durable and eventually executed by all nodes. In practice it means that a majority of nodes agree on what operations should be applied before the service will perform them.
Practically, it means that if the cluster is in a transition state - either electing a new leader after a failure or starting up, the collection update operations will be denied.
You may use the cluster REST API to check the state of the consensus.
Sharding
A Collection in Qdrant is made of one or more shards. A shard is an independent store of points which is able to perform all operations provided by collections. There are two methods of distributing points across shards:
- Automatic sharding: Points are distributed among shards by using a consistent hashing algorithm, so that shards are managing non-intersecting subsets of points. This is the default behavior.
- User-defined sharding: Available as of v1.7.0 - Each point is uploaded to a specific shard, so that operations can hit only the shard or shards they need. Even with this distribution, shards still ensure having non-intersecting subsets of points.
Each node knows where all parts of the collection are stored through the consensus protocol, so when you send a search request to one Qdrant node, it automatically queries all other nodes to obtain the full search result.
Choosing the right number of shards
When you create a collection, Qdrant splits the collection into shard_number shards. If left unset, shard_number is set to the number of nodes in your cluster when the collection was created. The shard_number cannot be changed without recreating the collection.
PUT /collections/{collection_name}
{
"vectors": {
"size": 300,
"distance": "Cosine"
},
"shard_number": 6
}To ensure all nodes in your cluster are evenly utilized, the number of shards must be a multiple of the number of nodes you are currently running in your cluster.
Note
Advanced use cases such as multitenancy may require an uneven distribution of shards. See Multitenancy.
We recommend creating at least 2 shards per node to allow future expansion without having to re-shard. Re-sharding should be avoided since it requires creating a new collection. In-place re-sharding is planned for a future version of Qdrant.
If you anticipate a lot of growth, we recommend 12 shards since you can expand from 1 node up to 2, 3, 6, and 12 nodes without having to re-shard. Having more than 12 shards in a small cluster may not be worth the performance overhead.
Shards are evenly distributed across all existing nodes when a collection is first created, but Qdrant does not automatically rebalance shards if your cluster size or replication factor changes (since this is an expensive operation on large clusters). See the next section for how to move shards after scaling operations.
Moving shards
Available as of v0.9.0
Qdrant allows moving shards between nodes in the cluster and removing nodes from the cluster. This functionality unlocks the ability to dynamically scale the cluster size without downtime. It also allows you to upgrade or migrate nodes without downtime.
Qdrant provides the information regarding the current shard distribution in the cluster with the Collection Cluster info API.
Use the Update collection cluster setup API to initiate the shard transfer:
POST /collections/{collection_name}/cluster
{
"move_shard": {
"shard_id": 0,
"from_peer_id": 381894127,
"to_peer_id": 467122995
}
}You likely want to select a specific shard transfer method to get desired performance and guarantees.
After the transfer is initiated, the service will process it based on the used transfer method keeping both shards in sync. Once the transfer is completed, the old shard is deleted from the source node.
In case you want to downscale the cluster, you can move all shards away from a peer and then remove the peer using the remove peer API.
DELETE /cluster/peer/{peer_id}After that, Qdrant will exclude the node from the consensus, and the instance will be ready for shutdown.
User-defined sharding
Available as of v1.7.0
Qdrant allows you to specify the shard for each point individually. This feature is useful if you want to control the shard placement of your data, so that operations can hit only the subset of shards they actually need. In big clusters, this can significantly improve the performance of operations that do not require the whole collection to be scanned.
A clear use-case for this feature is managing a multi-tenant collection, where each tenant (let it be a user or organization) is assumed to be segregated, so they can have their data stored in separate shards.
To enable user-defined sharding, set sharding_method to custom during collection creation:
httppythontypescriptrustjavacsharpgo
PUT /collections/{collection_name}
{
"shard_number": 1,
"sharding_method": "custom"
// ... other collection parameters
}In this mode, the shard_number means the number of shards per shard key, where points will be distributed evenly. For example, if you have 10 shard keys and a collection config with these settings:
{
"shard_number": 1,
"sharding_method": "custom",
"replication_factor": 2
}Then you will have 1 * 10 * 2 = 20 total physical shards in the collection.
Physical shards require a large amount of resources, so make sure your custom sharding key has a low cardinality.
For large cardinality keys, it is recommended to use partition by payload instead.
To specify the shard for each point, you need to provide the shard_key field in the upsert request:
httppythontypescriptrustjavacsharpgo
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1111,
"vector": [0.1, 0.2, 0.3]
},
]
"shard_key": "user_1"
}Using the same point ID across multiple shard keys is not supported* and should be avoided.
* When using custom sharding, IDs are only enforced to be unique within a shard key. This means that you can have multiple points with the same ID, if they have different shard keys. This is a limitation of the current implementation, and is an anti-pattern that should be avoided because it can create scenarios of points with the same ID to have different contents. In the future, we plan to add a global ID uniqueness check.
Now you can target the operations to specific shard(s) by specifying the shard_key on any operation you do. Operations that do not specify the shard key will be executed on all shards.
Another use-case would be to have shards that track the data chronologically, so that you can do more complex itineraries like uploading live data in one shard and archiving it once a certain age has passed.
Shard transfer method
Available as of v1.7.0
There are different methods for transferring a shard, such as moving or replicating, to another node. Depending on what performance and guarantees you’d like to have and how you’d like to manage your cluster, you likely want to choose a specific method. Each method has its own pros and cons. Which is fastest depends on the size and state of a shard.
Available shard transfer methods are:
stream_records: (default) transfer by streaming just its records to the target node in batches.snapshot: transfer including its index and quantized data by utilizing a snapshot automatically.wal_delta: (auto recovery default) transfer by resolving WAL difference; the operations that were missed.
Each has pros, cons and specific requirements, some of which are:
| Method: | Stream records | Snapshot | WAL delta |
|---|---|---|---|
| Version | v0.8.0+ | v1.7.0+ | v1.8.0+ |
| Target | New/existing shard | New/existing shard | Existing shard |
| Connectivity | Internal gRPC API (6335) | REST API (6333) Internal gRPC API (6335) | Internal gRPC API (6335) |
| HNSW index | Doesn’t transfer, will reindex on target. | Does transfer, immediately ready on target. | Doesn’t transfer, may index on target. |
| Quantization | Doesn’t transfer, will requantize on target. | Does transfer, immediately ready on target. | Doesn’t transfer, may quantize on target. |
| Ordering | Unordered updates on target1 | Ordered updates on target2 | Ordered updates on target2 |
| Disk space | No extra required | Extra required for snapshot on both nodes | No extra required |
To select a shard transfer method, specify the method like:
POST /collections/{collection_name}/cluster
{
"move_shard": {
"shard_id": 0,
"from_peer_id": 381894127,
"to_peer_id": 467122995,
"method": "snapshot"
}
}The stream_records transfer method is the simplest available. It simply transfers all shard records in batches to the target node until it has transferred all of them, keeping both shards in sync. It will also make sure the transferred shard indexing process is keeping up before performing a final switch. The method has two common disadvantages: 1. It does not transfer index or quantization data, meaning that the shard has to be optimized again on the new node, which can be very expensive. 2. The ordering guarantees are weak1, which is not suitable for some applications. Because it is so simple, it’s also very robust, making it a reliable choice if the above cons are acceptable in your use case. If your cluster is unstable and out of resources, it’s probably best to use the stream_records transfer method, because it is unlikely to fail.
The snapshot transfer method utilizes snapshots to transfer a shard. A snapshot is created automatically. It is then transferred and restored on the target node. After this is done, the snapshot is removed from both nodes. While the snapshot/transfer/restore operation is happening, the source node queues up all new operations. All queued updates are then sent in order to the target shard to bring it into the same state as the source. There are two important benefits: 1. It transfers index and quantization data, so that the shard does not have to be optimized again on the target node, making them immediately available. This way, Qdrant ensures that there will be no degradation in performance at the end of the transfer. Especially on large shards, this can give a huge performance improvement. 2. The ordering guarantees can be strong2, required for some applications.
The wal_delta transfer method only transfers the difference between two shards. More specifically, it transfers all operations that were missed to the target shard. The WAL of both shards is used to resolve this. There are two benefits: 1. It will be very fast because it only transfers the difference rather than all data. 2. The ordering guarantees can be strong2, required for some applications. Two disadvantages are: 1. It can only be used to transfer to a shard that already exists on the other node. 2. Applicability is limited because the WALs normally don’t hold more than 64MB of recent operations. But that should be enough for a node that quickly restarts, to upgrade for example. If a delta cannot be resolved, this method automatically falls back to stream_records which equals transferring the full shard.
The stream_records method is currently used as default. This may change in the future. As of Qdrant 1.9.0 wal_delta is used for automatic shard replications to recover dead shards.
Replication
Available as of v0.11.0
Qdrant allows you to replicate shards between nodes in the cluster.
Shard replication increases the reliability of the cluster by keeping several copies of a shard spread across the cluster. This ensures the availability of the data in case of node failures, except if all replicas are lost.
Replication factor
When you create a collection, you can control how many shard replicas you’d like to store by changing the replication_factor. By default, replication_factor is set to “1”, meaning no additional copy is maintained automatically. You can change that by setting the replication_factor when you create a collection.
Currently, the replication factor of a collection can only be configured at creation time.
httppythontypescriptrustjavacsharpgo
PUT /collections/{collection_name}
{
"vectors": {
"size": 300,
"distance": "Cosine"
},
"shard_number": 6,
"replication_factor": 2,
}This code sample creates a collection with a total of 6 logical shards backed by a total of 12 physical shards.
Since a replication factor of “2” would require twice as much storage space, it is advised to make sure the hardware can host the additional shard replicas beforehand.
Creating new shard replicas
It is possible to create or delete replicas manually on an existing collection using the Update collection cluster setup API.
A replica can be added on a specific peer by specifying the peer from which to replicate.
POST /collections/{collection_name}/cluster
{
"replicate_shard": {
"shard_id": 0,
"from_peer_id": 381894127,
"to_peer_id": 467122995
}
}You likely want to select a specific shard transfer method to get desired performance and guarantees.
And a replica can be removed on a specific peer.
POST /collections/{collection_name}/cluster
{
"drop_replica": {
"shard_id": 0,
"peer_id": 381894127
}
}Keep in mind that a collection must contain at least one active replica of a shard.
Error handling
Replicas can be in different states:
- Active: healthy and ready to serve traffic
- Dead: unhealthy and not ready to serve traffic
- Partial: currently under resynchronization before activation
A replica is marked as dead if it does not respond to internal healthchecks or if it fails to serve traffic.
A dead replica will not receive traffic from other peers and might require a manual intervention if it does not recover automatically.
This mechanism ensures data consistency and availability if a subset of the replicas fail during an update operation.
Node Failure Recovery
Sometimes hardware malfunctions might render some nodes of the Qdrant cluster unrecoverable. No system is immune to this.
But several recovery scenarios allow qdrant to stay available for requests and even avoid performance degradation. Let’s walk through them from best to worst.
Recover with replicated collection
If the number of failed nodes is less than the replication factor of the collection, then your cluster should still be able to perform read, search and update queries.
Now, if the failed node restarts, consensus will trigger the replication process to update the recovering node with the newest updates it has missed.
If the failed node never restarts, you can recover the lost shards if you have a 3+ node cluster. You cannot recover lost shards in smaller clusters because recovery operations go through raft which requires >50% of the nodes to be healthy.
Recreate node with replicated collections
If a node fails and it is impossible to recover it, you should exclude the dead node from the consensus and create an empty node.
To exclude failed nodes from the consensus, use remove peer API. Apply the force flag if necessary.
When you create a new node, make sure to attach it to the existing cluster by specifying --bootstrap CLI parameter with the URL of any of the running cluster nodes.
Once the new node is ready and synchronized with the cluster, you might want to ensure that the collection shards are replicated enough. Remember that Qdrant will not automatically balance shards since this is an expensive operation. Use the Replicate Shard Operation to create another copy of the shard on the newly connected node.
It’s worth mentioning that Qdrant only provides the necessary building blocks to create an automated failure recovery. Building a completely automatic process of collection scaling would require control over the cluster machines themself. Check out our cloud solution, where we made exactly that.
Recover from snapshot
If there are no copies of data in the cluster, it is still possible to recover from a snapshot.
Follow the same steps to detach failed node and create a new one in the cluster:
- To exclude failed nodes from the consensus, use remove peer API. Apply the
forceflag if necessary. - Create a new node, making sure to attach it to the existing cluster by specifying the
--bootstrapCLI parameter with the URL of any of the running cluster nodes.
Snapshot recovery, used in single-node deployment, is different from cluster one. Consensus manages all metadata about all collections and does not require snapshots to recover it. But you can use snapshots to recover missing shards of the collections.
Use the Collection Snapshot Recovery API to do it. The service will download the specified snapshot of the collection and recover shards with data from it.
Once all shards of the collection are recovered, the collection will become operational again.
Temporary node failure
If properly configured, running Qdrant in distributed mode can make your cluster resistant to outages when one node fails temporarily.
Here is how differently-configured Qdrant clusters respond:
- 1-node clusters: All operations time out or fail for up to a few minutes. It depends on how long it takes to restart and load data from disk.
- 2-node clusters where shards ARE NOT replicated: All operations will time out or fail for up to a few minutes. It depends on how long it takes to restart and load data from disk.
- 2-node clusters where all shards ARE replicated to both nodes: All requests except for operations on collections continue to work during the outage.
- 3+-node clusters where all shards are replicated to at least 2 nodes: All requests continue to work during the outage.
Consistency guarantees
By default, Qdrant focuses on availability and maximum throughput of search operations. For the majority of use cases, this is a preferable trade-off.
During the normal state of operation, it is possible to search and modify data from any peers in the cluster.
Before responding to the client, the peer handling the request dispatches all operations according to the current topology in order to keep the data synchronized across the cluster.
- reads are using a partial fan-out strategy to optimize latency and availability
- writes are executed in parallel on all active sharded replicas
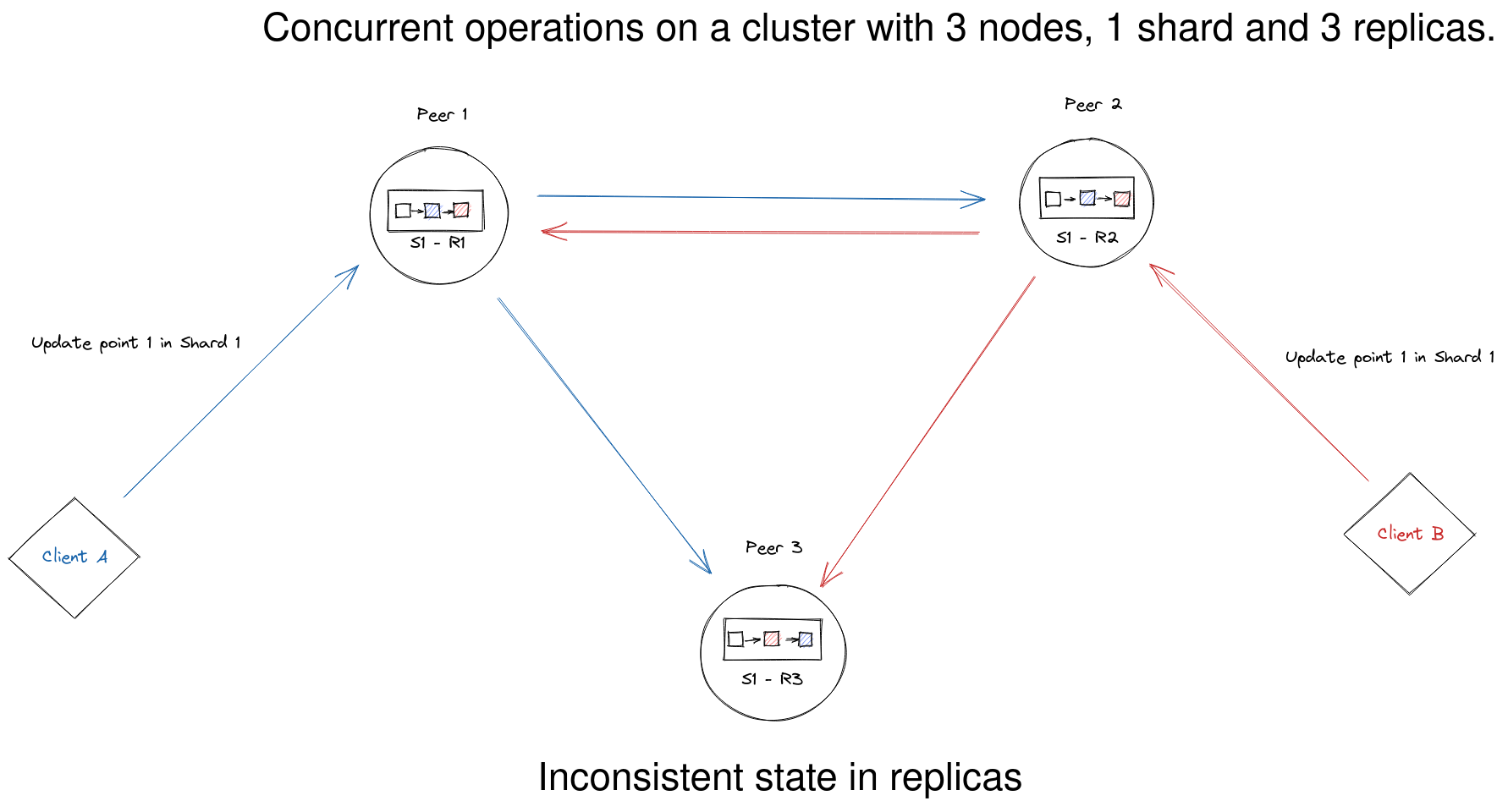
However, in some cases, it is necessary to ensure additional guarantees during possible hardware instabilities, mass concurrent updates of same documents, etc.
Qdrant provides a few options to control consistency guarantees:
write_consistency_factor- defines the number of replicas that must acknowledge a write operation before responding to the client. Increasing this value will make write operations tolerant to network partitions in the cluster, but will require a higher number of replicas to be active to perform write operations.- Read
consistencyparam, can be used with search and retrieve operations to ensure that the results obtained from all replicas are the same. If this option is used, Qdrant will perform the read operation on multiple replicas and resolve the result according to the selected strategy. This option is useful to avoid data inconsistency in case of concurrent updates of the same documents. This options is preferred if the update operations are frequent and the number of replicas is low. - Write
orderingparam, can be used with update and delete operations to ensure that the operations are executed in the same order on all replicas. If this option is used, Qdrant will route the operation to the leader replica of the shard and wait for the response before responding to the client. This option is useful to avoid data inconsistency in case of concurrent updates of the same documents. This options is preferred if read operations are more frequent than update and if search performance is critical.
Write consistency factor
The write_consistency_factor represents the number of replicas that must acknowledge a write operation before responding to the client. It is set to one by default. It can be configured at the collection’s creation time.
httppythontypescriptrustjavacsharpgo
PUT /collections/{collection_name}
{
"vectors": {
"size": 300,
"distance": "Cosine"
},
"shard_number": 6,
"replication_factor": 2,
"write_consistency_factor": 2,
}Write operations will fail if the number of active replicas is less than the write_consistency_factor.
Read consistency
Read consistency can be specified for most read requests and will ensure that the returned result is consistent across cluster nodes.
allwill query all nodes and return points, which present on all of themmajoritywill query all nodes and return points, which present on the majority of themquorumwill query randomly selected majority of nodes and return points, which present on all of them1/2/3/etc - will query specified number of randomly selected nodes and return points which present on all of them- default
consistencyis1
httppythontypescriptrustjavacsharpgo
POST /collections/{collection_name}/points/query?consistency=majority
{
"query": [0.2, 0.1, 0.9, 0.7],
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"limit": 3
}Write ordering
Write ordering can be specified for any write request to serialize it through a single “leader” node, which ensures that all write operations (issued with the same ordering) are performed and observed sequentially.
weak(default) ordering does not provide any additional guarantees, so write operations can be freely reordered.mediumordering serializes all write operations through a dynamically elected leader, which might cause minor inconsistencies in case of leader change.strongordering serializes all write operations through the permanent leader, which provides strong consistency, but write operations may be unavailable if the leader is down.
Some shard transfer methods may affect ordering guarantees.
httppythontypescriptrustjavacsharpgo
PUT /collections/{collection_name}/points?ordering=strong
{
"batch": {
"ids": [1, 2, 3],
"payloads": [
{"color": "red"},
{"color": "green"},
{"color": "blue"}
],
"vectors": [
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
[0.1, 0.1, 0.9]
]
}
}Listener mode
This is an experimental feature, its behavior may change in the future.
In some cases it might be useful to have a Qdrant node that only accumulates data and does not participate in search operations. There are several scenarios where this can be useful:
- Listener option can be used to store data in a separate node, which can be used for backup purposes or to store data for a long time.
- Listener node can be used to syncronize data into another region, while still performing search operations in the local region.
To enable listener mode, set node_type to Listener in the config file:
storage:
node_type: "Listener"Listener node will not participate in search operations, but will still accept write operations and will store the data in the local storage.
All shards, stored on the listener node, will be converted to the Listener state.
Additionally, all write requests sent to the listener node will be processed with wait=false option, which means that the write oprations will be considered successful once they are written to WAL. This mechanism should allow to minimize upsert latency in case of parallel snapshotting.
Consensus Checkpointing
Consensus checkpointing is a technique used in Raft to improve performance and simplify log management by periodically creating a consistent snapshot of the system state. This snapshot represents a point in time where all nodes in the cluster have reached agreement on the state, and it can be used to truncate the log, reducing the amount of data that needs to be stored and transferred between nodes.
For example, if you attach a new node to the cluster, it should replay all the log entries to catch up with the current state. In long-running clusters, this can take a long time, and the log can grow very large.
To prevent this, one can use a special checkpointing mechanism, that will truncate the log and create a snapshot of the current state.
To use this feature, simply call the /cluster/recover API on required node:
POST /cluster/recoverThis API can be triggered on any non-leader node, it will send a request to the current consensus leader to create a snapshot. The leader will in turn send the snapshot back to the requesting node for application.
In some cases, this API can be used to recover from an inconsistent cluster state by forcing a snapshot creation.
- Weak ordering for updates: All records are streamed to the target node in order. New updates are received on the target node in parallel, while the transfer of records is still happening. We therefore have
weakordering, regardless of what ordering is used for updates. ↩︎ ↩︎ - Strong ordering for updates: A snapshot of the shard is created, it is transferred and recovered on the target node. That ensures the state of the shard is kept consistent. New updates are queued on the source node, and transferred in order to the target node. Updates therefore have the same ordering as the user selects, making
strongordering possible. ↩︎ ↩︎ ↩︎ ↩︎