Kubernetes Event-driven Autoscaling
KEDA is a Kubernetes-based Event Driven Autoscaler. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needing to be processed.
KEDA is a single-purpose and lightweight component that can be added into any Kubernetes cluster. KEDA works alongside standard Kubernetes components like the Horizontal Pod Autoscaler and can extend functionality without overwriting or duplication. With KEDA you can explicitly map the apps you want to use event-driven scale, with other apps continuing to function. This makes KEDA a flexible and safe option to run alongside any number of any other Kubernetes applications or frameworks.
How KEDA works
KEDA performs three key roles within Kubernetes:
- Agent — KEDA activates and deactivates Kubernetes Deployments to scale to and from zero on no events. This is one of the primary roles of the
keda-operatorcontainer that runs when you install KEDA. - Metrics — KEDA acts as a Kubernetes metrics server that exposes rich event data like queue length or stream lag to the Horizontal Pod Autoscaler to drive scale out. It is up to the Deployment to consume the events directly from the source. This preserves rich event integration and enables gestures like completing or abandoning queue messages to work out of the box. The metric serving is the primary role of the
keda-operator-metrics-apiservercontainer that runs when you install KEDA. - Admission Webhooks - Automatically validate resource changes to prevent misconfiguration and enforce best practices by using an admission controller. As an example, it will prevent multiple ScaledObjects to target the same scale target.
Architecture
The diagram below shows how KEDA works in conjunction with the Kubernetes Horizontal Pod Autoscaler, external event sources, and Kubernetes’ etcd data store:
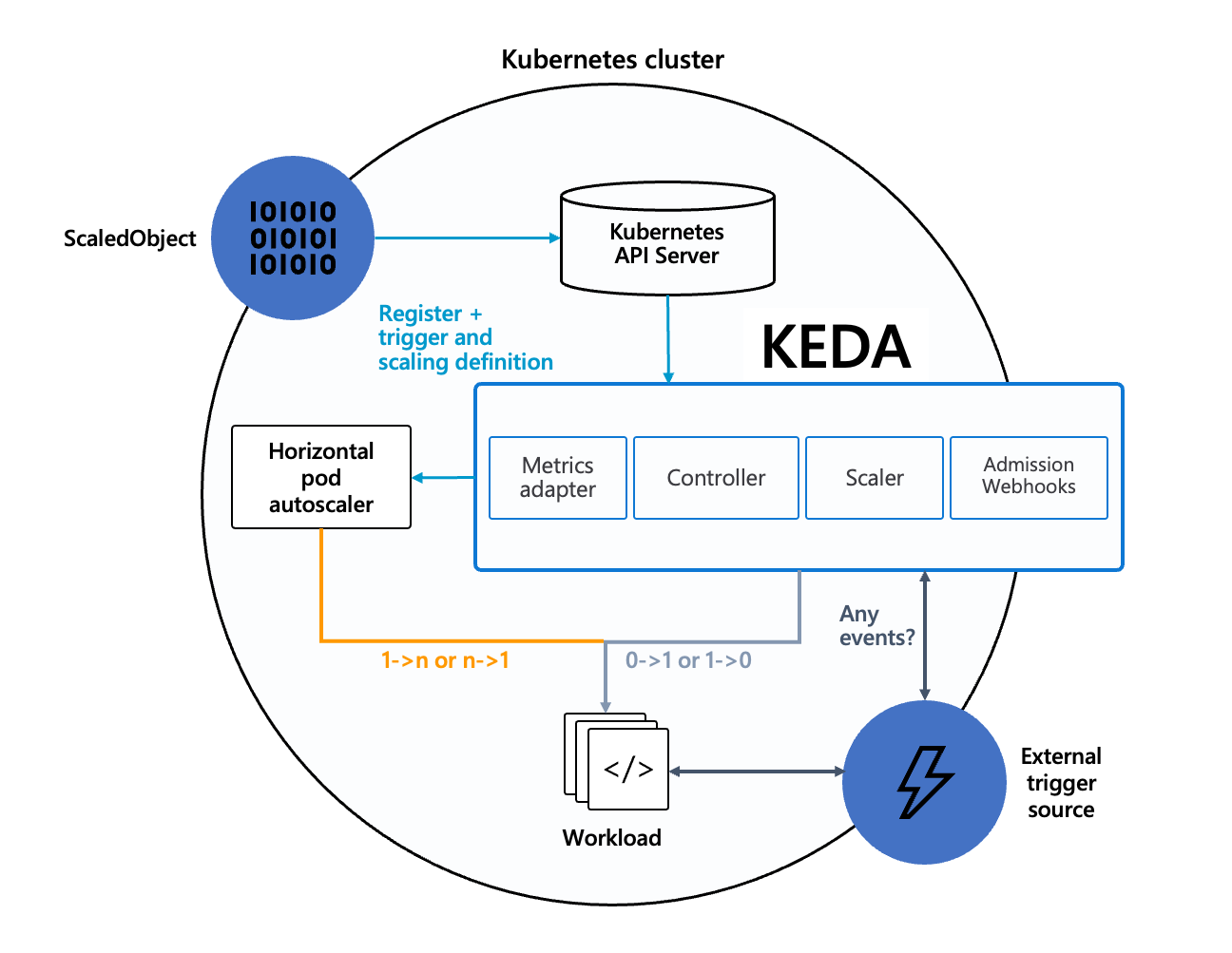
Event sources and scalers
KEDA has a wide range of scalers that can both detect if a deployment should be activated or deactivated, and feed custom metrics for a specific event source. The following scalers are available:
- RabbitMQ Queue
- Prometheus
- NATS JetStream
Custom Resources (CRD)
When you install KEDA, it creates four custom resources:
scaledobjects.keda.shscaledjobs.keda.shtriggerauthentications.keda.shclustertriggerauthentications.keda.sh
These custom resources enable you to map an event source (and the authentication to that event source) to a Deployment, StatefulSet, Custom Resource or Job for scaling.
ScaledObjectsrepresent the desired mapping between an event source (e.g. Rabbit MQ) and the Kubernetes Deployment, StatefulSet or any Custom Resource that defines/scalesubresource.ScaledJobsrepresent the mapping between event source and Kubernetes Job.ScaledObject/ScaledJobmay also reference aTriggerAuthenticationorClusterTriggerAuthenticationwhich contains the authentication configuration or secrets to monitor the event source.
Scaling objects
Scaling Deployments and StatefulSets
Deployments and StatefulSets are the most common way to scale workloads with KEDA.
It allows you to define the Kubernetes Deployment or StatefulSet that you want KEDA to scale based on a scale trigger. KEDA will monitor that service and based on the events that occur it will automatically scale your resource out/in accordingly.
Behind the scenes, KEDA acts to monitor the event source and feed that data to Kubernetes and the HPA (Horizontal Pod Autoscaler) to drive rapid scale of a resource. Each replica of a resource is actively pulling items from the event source. With KEDA and scaling Deployments/StatefulSet you can scale based on events while also preserving rich connection and processing semantics with the event source (e.g. in-order processing, retries, deadletter, checkpointing).
Example
For example, if you wanted to use KEDA with an Apache Kafka topic as event source, the flow of information would be:
- When no messages are pending processing, KEDA can scale the deployment to zero.
- When a message arrives, KEDA detects this event and activates the deployment.
- When the deployment starts running, one of the containers connects to Kafka and starts pulling messages.
- As more messages arrive at the Kafka Topic, KEDA can feed this data to the HPA to drive scale out.
- Each replica of the deployment is actively processing messages. Very likely, each replica is processing a batch of messages in a distributed manner.